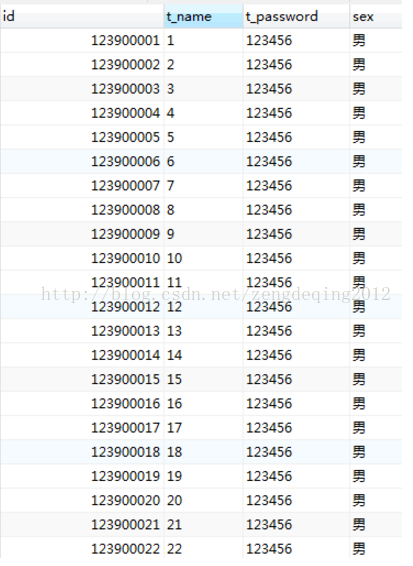
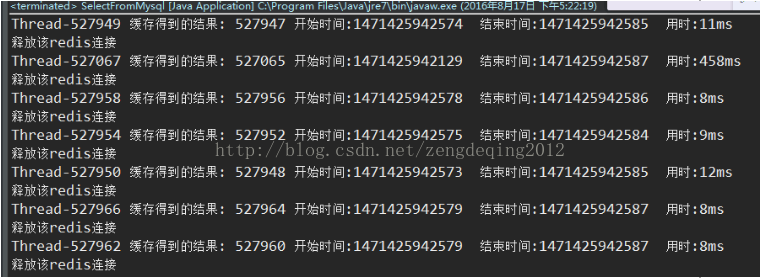
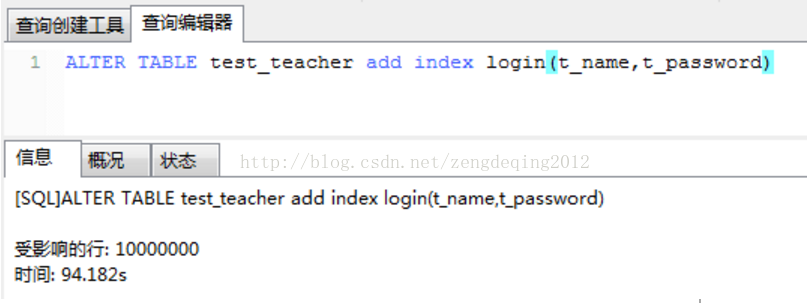
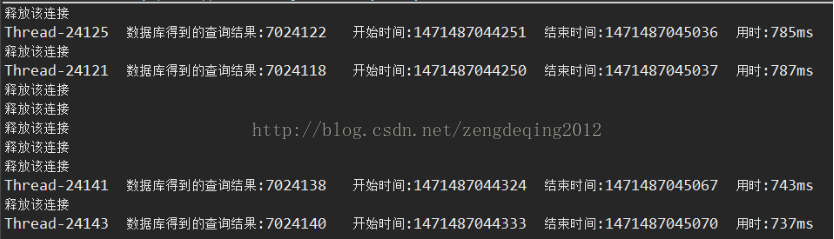
所谓独创的能力,就是经过深思的模仿。
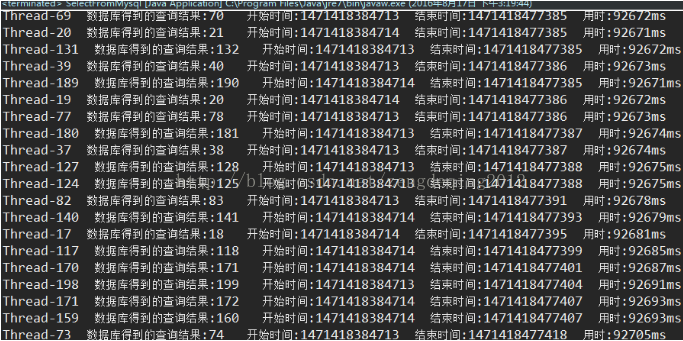
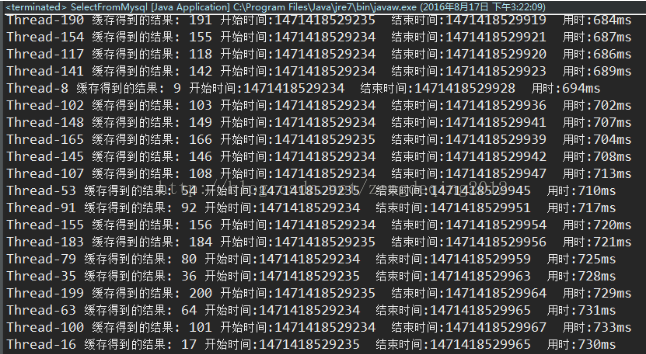
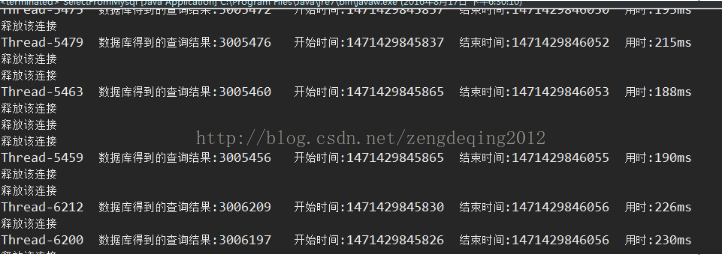
package select;import redis.clients.jedis.JedisPool;import redis.clients.jedis.JedisPoolConfig;public class SelectFromMysql {public static void main(String[] args) {JedisPool pool;JedisPoolConfig config = new JedisPoolConfig();//创建redis连接池// 设置最大连接数,-1无限制config.setMaxTotal(300);// 设置最大空闲连接config.setMaxIdle(100);// 设置最大阻塞时间,记住是毫秒数millisecondsconfig.setMaxWaitMillis(100000);// 创建连接池pool = new JedisPool(config, "127.0.0.1", 6379,200000);for (int i =9222000; i <=9222200; i++) {//这里自己设置用多少线程并发访问 String teacherName=String.valueOf(i); new ThreadToMysql(teacherName, "123456",pool).start(); } }}package select;import java.sql.Connection;import java.sql.DriverManager;import java.sql.ResultSet;import java.sql.SQLException;import java.sql.Statement;import redis.clients.jedis.Jedis;import redis.clients.jedis.JedisPool;public class ThreadToMysql extends Thread {public String teacherName;public String password;public JedisPool pool;public ThreadToMysql(String teacherName, String password,JedisPool pool) {//构造函数传入要查询登录的老师姓名和密码this.teacherName=teacherName;this.password=password;this.pool=pool;}public void run() {Jedis jedis = pool.getResource();Long startTime=System.currentTimeMillis();//开始时间if (jedis.get(teacherName)!=null) {Long entTime=System.currentTimeMillis();//开始时间System.out.println(currentThread().getName()+" 缓存得到的结果: "+jedis.get(teacherName)+" 开始时间:"+startTime+" 结束时间:"+entTime+" 用时:" +(entTime-startTime)+"ms");pool.returnResource(jedis);System.out.println("释放该redis连接");} else {String url = "jdbc:mysql://127.0.0.1/teacher";String name = "com.mysql.jdbc.Driver";String user = "root";String password = "123456";Connection conn = null;try {Class.forName(name);conn = DriverManager.getConnection(url, user, password);//获取连接conn.setAutoCommit(false);//关闭自动提交,不然conn.commit()运行到这句会报错} catch (ClassNotFoundException e1) {e1.printStackTrace();} catch (SQLException e) {e.printStackTrace();}if (conn!=null) {String sql="select t_name from test_teacher where t_name='"+teacherName+"' and t_password='"+password+"' ";//SQL语句String t_name=null;try {Statement stmt=conn.createStatement();ResultSet rs=stmt.executeQuery(sql);//获取结果集if (rs.next()) {t_name=rs.getString("t_name");jedis.set(teacherName, t_name);System.out.println("释放该连接");}conn.commit();stmt.close();conn.close();} catch (SQLException e) {e.printStackTrace();}finally {pool.returnResource(jedis);System.out.println("释放该连接");}Long end=System.currentTimeMillis();System.out.println(currentThread().getName()+" 数据库得到的查询结果:"+t_name+" 开始时间:"+startTime+" 结束时间:"+end+" 用时:"+(end-startTime)+"ms");} else {System.out.println(currentThread().getName()+"数据库连接失败:");}}}}我的数据库表数据是这样的。可以看到我的t_name是1-10000000,密码固定123456.利用循环创建线程很好做传入循环的次数作为查询的t_name就行了