才能是来自独创性。独创性是思维、观察、理解和判断的一种独特的方式。
一、什么是P2P
对等网络(PeertoPeer,简称P2P)也称为对等连接,是一种新的通信模式,每个参与者具有同等的能力,可以发起一个通信会话。
这个定义有点抽象,下面就来简单地解释一下。粗略地讲,应用程序可以设计成采用客户机/服务器体系结构或对等体系结构(P2P)。我们日常生活中的许多应用程序,包括web、电子邮件和DNS,都是使用客户机/服务器体系结构;而文件分发,例如大家熟悉的迅雷下载等,就是使用P2P文件分发的技术,使用的就是对待体系结构(P2P)。
对于客户机/服务器体系结构,它要求总是打开的基础设施服务器。相反,使用P2P体系结构,对总是打开的基础设施服务器有最小的(或者没有)依赖,任意间断连接的主机对都称为对等方,各个对等方直接通信。对等方并不为服务提供商所有,而是为用户控制的设备。
二、P2P文件分发
下面通过一个具体的应用来研究P2P,这个应用是从单一服务器向大量主机(对等方)分发大文件。
在客户机/服务器文件分发中,服务器必须向每个客户机发送该文件的一个拷贝,这同时给服务器造成了极大的负担,并且消耗了大量的服务器带宽。在P2P文件分发中,每个对等方(即对应客户机/服务器体系结构中的客户机)都能够重新分发其所有的该文件的任何部分,从而协助服务器进行分发。
1、客户机/服务器体系结构 VS P2P体系结构
首先我们假设文件的长度为F,服务器上传的速率为U,下载速率为D,而客户机有N台,每台的上传速率为ui(i=1、2...N),每台的下载速率为di(i=1、2...N)。
由于每一次文件的分发都涉及服务器上传文件和客户机(或对等方)下载文件。在下面的讨论中,我们假设F、U、D、ui、di均不变,而N,即对等方数量却是可变的。
首先,对于客户机/服务器体系结构,服务器上传N个文件(因为有N个客户,每个客户一个文件的副本)所需要的时间至少为NF/U。而下载速率最小(用dmin表示)的对等方不可能在F/dmin秒内获得该 文件的所有F比特,所以使用客户机/服务器体系结构分发文件所需的时间为
Dcs = max{NF/U,F/dmin}
即所需要的最小时间由下载文件最长时间和上传文件中的较大者决定,其实这也是很自然的事,因为分发时间,要不就是服务器上传这N个文件用时多,要不就是对等方下载这N个文件用时多。然而,我们可以看到NF/U会随着N的增大而线性增大,而F/dmin却是个常值。也就是说当N达到一定的程度时,它必然大于F/dmin,也就变成是Dcs的值,即Dcs = NF/U。
然后,对于P2P体系结构,其中每个对等方都能够帮助服务器来分发文件。也就是说,当一个对等方接收到文件数据时,它可以利用自己的上载能力重新将数据分发给其他对等方。
在分发的开始,只有服务器拥有文件。为了使对等方得到该文件,服务器必须经其接入链路至少发送一次该文件。因此最小分发时间至少是F/U。因为在P2P体系结构中,服务器发送一次文件就可能不用再次发送了,因为其他对等方可以从拥有该文件的对等方中获得。
与客户机/服务器体系结构相同,下载速率最小的对等方不可能在F/dmin秒之内获得文件F的所有比特。因此最小的分发时间也可能是F/dmin。
最后,系统的总上载能力等于服务器的上载速率加上每个对等方的上载速率,即Utotal=U+u1+u2...+uN。系统必须向N个对等方的都交付(上载)F比特,因此总的交付为NF比特。所以最小分发时间至少是NF/(U+u1+u2...+uN)。
综上所述,使用P2P体系结构分发文件所需要的时间为
Dp2p = max{F/U, F/dmin, NF/(U+u1+u2...+uN)}
即最小分发时间由服务器上传的时间,对等方下载的最长时间和所有对待方上传下载的时间来决定。同样,因为F/U, F/dmin都是常数,所以当N达到一定值后,NF/(U+u1+u2...+uN)就会大于前面的两者,成为分发文件所需要的时间,即Dp2p = NF/(U+u1+u2...+uN)。从表达式中,我们可以看到,当N的值增大时,由于对等方的数量也能加了,所以U+u1+u2...+uN的值也会随之增大,所以函数并不像客户机/服务器体系结构中函数那样,分发时间会线性地增加,它的曲线与对数函数(如log2N)的曲线相似。所以当N的值较大时,P2P体系结构分发文件所需要时间远比客户机/服务器体系结构的小。
2、BitTorrent——用于文件分发的流行P2P协议
前面用数学的方法说明了基于客户机/服务器体系结构和基于P2P体系结构的文件分发所需的时间的差别,下面来说一下,这个P2P文件分发是如何实现的。下面以使用BitTorrent协议为例子说明。
在BitTorrent中,把参与一个特定文件分发的所有对等方的集合称为一个洪流。在一个洪流中,对等方彼此下载等长度的文件块,块长度通常为256KB。当一个对等方开始加入一个洪流时,它没有文件块。但是随着时间的推移,它将累积到越来越多的文件块。当它下载文件块时,也为其他对等方上载多个文件块。对待方一旦获得了整个文件,它可以离开洪流,或留在洪流中,为其他对等方上载文件块。同时,任何一个对等方可以在任何时候离开洪流,以后也可以重新加入洪流。
这里有二个问题,1)我们的主机或设备加入一个洪流中时如何知道它有哪些对等方,即它如何知道它要向哪些主机请求所需要的文件。2)我们在下载文件时,如果确定我们所需要的文件块是哪一块,换句话说就是,文件有很多块组成,而我们下载时并不按文件原有的顺序下载,那么我如何确定我还需要下载哪些块来让这个文件变得完整。
首先回答第一个问题,每个洪流具有一个基础设施节点,称为追踪器。当一个对等方加入洪流时,它向追踪器注册,并周期性地通知追踪器它仍在洪流中。一个特定的洪流可能在任意时刻拥有数以百计或千计的对等方。当一个新的对等方A加入洪流时,追踪器随机地从参与对等方集合中选择一些对等方,并将这些对等方的IP地址发送给A,A持有对等方的这张列表,试图与该列表上的对等方创建并行的TCP连接,与A成功地创建TCP连接的对等方称为“邻近对等方”。随着时间的推移,其中的一些对待方可能离开,而另一些对等方可能试图与A创建TCP连接,就像A之前所做的那样。这样我们就可以知道我们要下载的文件所在洪流中有哪些的对等方。
再来回答第二个问题,在任何时刻,每个对等方都具有某文件块的子集,且不同的对等方具有不同的文件块子集。A周期性询问每个邻近对等方所具有的块列表并获得其邻居的块列表,因此A将对它当前还没有的块发出请求。同时由于在洪流中的每一个对等方既下载又上传,所以A还应决定它请求的块应该发送给它的哪些邻居。通常在请求块的过程中,使用一种叫最稀罕优先的技术,即根据A没有的块从它的邻居中确定最稀罕的块(即那些在它的邻居中拷贝数量最少的那些块),并优先请求这些最稀罕的块。这样做的目的也是很明显,就是让每个块在洪流中的拷贝数量大致相等,这样同时也能提高总的下载速率,因为下载不会卡在某个文件块的下载中。
三、P2P区域搜索信息
P2P的另一个重要应用就是信息索引,即信息到主机位置的映射。
为了说明什么是索引,举个例子说明吧,P2P文件共享系统中有一个索引,它动态地跟踪这些对等方可供共享的文件。该索引维护了一个记录,记录将有关拷贝的信息映射到具有拷贝对等方的IP地址。当一个对等方加入系统时,它通知系统它所拥有的文件索引。当一个用户希望获得一个文件时,他搜索索引以定位该文件的拷贝的位置。
注:P2P文件分发与P2P文件共享还是有一定的区别的,P2P的文件共享有可能发生在不同的时段,例如,现在收到的文件,1小时后才需上传。P2P的文件共享也有可能发生在不同的文件,例如,需要下载A文件,却为其他用户提供B文件。而P2P的文件分发更多是针对单一文件,在下载的同一时间为其他用户提供上传服务,这是一个协同处理的过程。
1、集中式索引
由一台大型服务器(或服务器场)来提供索引服务。当用户启动P2P文件共享应用程序时,该应用程序将它的IP地址以及可供共享的文件名称通知索引服务器。索引服务器收集可共享的对象,建立集中式的动态数据库(对象名称到IP地址的映射)。
它有如下的缺点:
1、单点故障
2、性能瓶颈
3、可靠性差
这种索引方式的特点是:文件传输是分散的(P2P的),但定位内容的过程是高度集中的(客户机/服务器)。
2、查询洪泛
查询洪泛采用完全分布式的方法,索引全面地分布在对等方的区域中,对等方形成了一个抽象的逻辑网络,称为覆盖网络。当A要定位索引(例如abc)时,它向它的所有邻居发送一条查询报文(包含关键字abc)。A的所有邻居向它们的所有邻居转发该报文,这些邻居又接着向它们的所有邻居转发该报文等。如果其中一个对等主与索引(abc)配置,则返回一个查询命中报文。
但是这种简单的方法却有一个致命的缺点,就是它会产生大量的流量。
一个解决办法就是采用范围受限查询洪泛。设置一个计数值,对等方向其邻居转发请求之前就将对等方的计数字段减1,当一个对等方的计数字段为0时,停止查询。
3、层次覆盖
该方法结合了集中式索引和查询洪泛的优点,与查询洪泛相似,层次覆盖设计并不使用专用的服务器来跟踪和索引文件。不同的是在层次覆盖中并非所有的对等方都是平等的。
它的示意图如下:
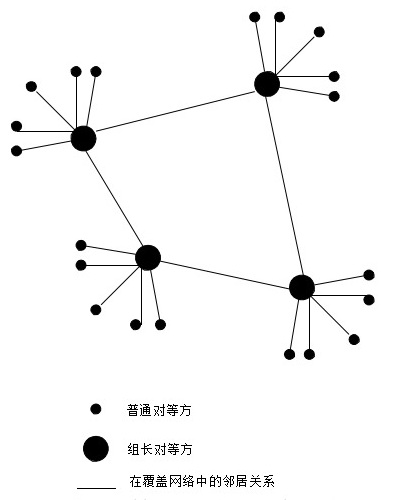
超级对等方(组长对等方)维护着一个索引,该索引包括了其子对等方(普通对待方)正在共享的所有文件的标识符、有关文件的元数据和保持这些文件的子对等方的IP地址。而超级对等方通常也只是一个普通的对等方。超级对等方之间相互建立TCP连接,从而形成一个覆盖网络,超级对等方可以向其相信超级对等方转发查询,但是仅在超级对等方使用范围受限查询洪泛。
当某对等方进行索引时,它向其超级对等方发送带有关键词的查询。超级对等方则用其具有相关文件的子对等方的IP地址进行响应,该超级对等方还可能向一个或多个相邻的超级对等方转发该查询。如果某相邻对等方收到了这样一个请求,它也会用具有匹配文件的子对等方的IP地址进行响应。
与受限查询洪泛设计相比,层次覆盖设计允许数量多得多的对等方检查匹配,而不会产生过量的查询流量。
通过这两种P2P常用应用的介绍,大家对P2P应该有一定的认识了吧!
原文链接:http://blog.csdn.net/ljianhui/article/details/16911151

